Automatic text tagging by Deep Learning using just few lines of code
Code available at: https://github.com/opsabarsec/NLP--film-genres-from-synopsis
Extracting keywords from a text is one of the widest application of natural language processing (NLP). Depending on a specific problem, approaches can be various. Unsupervised learning can be used to identify, for example, a spam message when few special keywords are obtained. When it comes to tags assignment, supervised learning produces better predictions. In this case, I applied it to a Kaggle challenge for which the 5 most probable genres of a movie have to be predicted from its synopsis[1].
Text preprocessing
Regardless of the ML algorithm used for the task, few preliminary steps are necessary:
- Clean up abbreviations and special characters from the synopsis text
- Lemmatization
- Text trimming. The graph below shows that average length is 25 words and there are only few synopsis shorter than that. However even fewer containing very long text can produce an unbalanced dataset. For this there is a padding function within the Python deep learning library Keras (from keras.preprocessing.sequence import pad_sequences). Padding makes the shorter sentences as long as the others by filling the shortfall by zeros. But on the other hand, it also trims the longer ones to the same length(maxlen) as the short ones. In this case, we have set the max length to be 150.

The preprocessed dataframe is shown below

As the preliminary steps are over, target features have to be encoded to be fed to the ML algorithm. Easy done in Python and we obtain from the tags/genres column a sparse matrix shown in Figure 3

Finally the model!
Classic ML model did not produce good predictions (accuracy below 15%)

Observing similar Kaggle competitions, long-short-term-memory (LSTM) neural networks are widely used for NLP, and following an example for “toxic comments tags”[2] a simple deep learning could be built based on our train dataset.
#initialize parametersinp = Input(shape=(maxlen, )) #maxlen defined earlierembed_size = 128# Neural network backbone
x = Embedding(max_features, embed_size)(inp)
x = LSTM(64, return_sequences=True,name='lstm_layer')(x)
x = GlobalMaxPool1D()(x)
x = Dropout(0.1)(x)
x = Dense(50, activation="relu")(x)
x = Dropout(0.1)(x)
x = Dense(len(y_bin.columns), activation="softmax")(x)
hyperparameters could be further tuned, layers can be added to the neural network but with just a couple of training loops over the whole set (epochs)
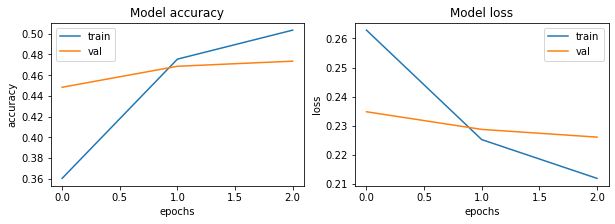
an accuracy of 50% could be obtained over the validation set. More epochs would eventually lead to overfitting for the above algorithm, but to improve predictions both preliminary steps and modelling can be adjusted. In this case a good baseline was reached with a very simple code. The n most probable tags/genres could be easily obtained from the prediction vector using the code below
def top_5_predictions(df):
N = 5
cols = df.columns[:-1].tolist()
a = df[cols].to_numpy().argsort()[:, :-N-1:-1]
c = np.array(cols)[a]
d = df[cols].to_numpy()[np.arange(a.shape[0])[:, None], a]
df1 = pd.DataFrame(c).rename(columns=lambda x : f'max_{x+1}_col')
predicted_genres = df1["max_1_col"] + ' ' + df1["max_2_col"]+ ' ' +df1["max_3_col"]+ ' ' + df1["max_4_col"]+ ' '+df1["max_5_col"]
return predicted_genresConclusions
LSTM can be an extremely powerful NLP tool and are getting easier and easier to be implemented in Python. These models can be easily exported using pickle library and deployed to a REST API using Flask. Keywords can then be extracted by sending the synopsis text using for example the software “Postman” [3].
References
